Fortaleza, Sábado, 20 Abril 2024
Tecnologia da Informação
Mostrando itens por tag: Banco de Dados
Domingo, 01 Abril 2018 14:32
Análise de Plataforma Bussines Intelligence

- TITULO: Business Intelligence.
- TEMA: Business Intelligence: Open Souce ou Software Proprietário?
- DELIMITAÇÃO DO TEMA: Business Intelligence: O que mais influência na hora da escolha para ferramentas de BI, abordaremos principalmente o tema: Ferramentas Open Souce ou Software Proprietário?
- PROBLEMA:
O que mais se questiona no momento em que uma empresa vai iniciar o processo de construção de um BI é como tudo vai ser feito. As ferramentas que vão ser utilizadas vão depender de muitos fatores, inclusive do tamanho da empresa, do volume de informações que serão carregadas e principalmente na eficiência na hora de tomar decisões.
Investir pesado em uma ferramenta cara para simplesmente gerar relatório é um erro que pode custar caro para a organização. Por outro lado, adotar uma ferramenta que não permita tomar decisões rápidas e seguras também é um fator que pode prejudicar o andamento do negócio.
- HIPÓTESE:
Estudos de viabilidade e uma detalhada análise desde a estrutura da empresa até chegar ao propósito final para descobrir a real intenção e os objetivos finais a serem alcançados com a implantação do BI é algo que não pode ficar de fora.
Neste caso, o maior desafio dos profissionais responsáveis por construir todo o sistema de BI é entender o que a empresa precisa para trabalhar com eficiência e tomar as decisões que possam agregar valor ao negócio além de implantar as ferramentas corretas, o que leva tempo de análise e estudos de viabilidade.
MITO: Simplesmente implantar um sistema de BI com as melhores ferramentas do mercado é o que vai definir se uma empresa vai ter ou não sucesso na tomada de decisão. Ou ainda, adotar ferramentas livres é fator que vai definir o sucesso da organização. Estes são mitos que podem levar a grandes frustrações ou ainda, definir o futuro das organizações.
OPEN SOURCE (CÓDIGO ABERTO):
O termo código aberto, ou open source em inglês, foi criado pela OSI (Open Source Initiative) e se difere de um software livre por não respeitar as quatro liberdades definidas pela Free Software Foundation (FSF), compartilhadas também pelo projeto Debian, nomeadamente em "Debian Free Software Guidelines (DFSG)".
Qualquer licença de software livre é também uma licença de código aberto (Open Source), mas o contrário nem sempre é verdade. Enquanto a FSF usa o termo "Software Livre" envolta de um discurso baseado em questões éticas, direitos e liberdade, a OSI usa o termo "Código Aberto" sob um ponto de vista puramente técnico, evitando (propositadamente) questões éticas. Esta nomenclatura e este discurso foram cunhados por Eric Raymond e outros fundadores da OSI com o objetivo de apresentar o software livre a empresas de uma forma mais comercial evitando o discurso ético.
A história do movimento Open Source confunde-se com as origens do UNIX, da Internet e da cultura "hacker".
O rótulo "Open Source" surgiu em uma reunião em fevereiro de 1998. Tal debate juntou personalidades que se tornaram verdadeiras referências no que diz respeito ao Open Source, como Todd Anderson, Chris Peterson (Foresight Institute), Jon "Maddog" Hall e Larry Augustin (Linux International), Sam Ockman (Silicon Valley Linux User's Group) e Eric Raymond.
Como a diferença entre os movimentos "Software Livre" e "Código Aberto" está apenas na argumentação em prol dos mesmos softwares, é comum que esses grupos se unam em diversas situações ou que sejam citados de uma forma agregadora através da sigla "FLOSS" (Free/Libre and Open Source Software).
Os defensores do movimento Open Source sustentam que não se trata de algo anticapitalista ou anarquista, mas de uma alternativa ao modelo de negócio para a indústria de software. O modelo colaborativo de produção intelectual oferece um novo paradigma para o direito autoral. Algumas grandes empresas como IBM, HP, Intel e Dell também têm investido no software de código aberto, juntando esforços para a criação do Open Source Development Lab (OSDL), instituição destinada à criação de tecnologias de código aberto.
DEFINIÇÃO DE OPEN SOURCE:
A definição do Open Source foi criada pela Open Source Iniciative (OSI) a partir do texto original da Debian Free Software Guidelines (DFSG) e determina que um programa de código aberto deve garantir:
DISTRIBUIÇÃO LIVRE:
A licença não deve restringir de nenhuma maneira a venda ou distribuição do programa gratuitamente, como componente de outro programa ou não.
CÓDIGO FONTE:
O programa deve incluir seu código fonte e deve permitir a sua distribuição também na forma compilada. Se o programa não for distribuído com seu código fonte, deve haver algum meio de se obter o mesmo seja via rede ou com custo apenas de reprodução. O código deve ser legível e inteligível por qualquer programador.
TRABALHOS DERIVADOS:
A licença deve permitir modificações e trabalhos derivados, e deve permitir que eles sejam distribuídos sobre os mesmos termos da licença original.
INTEGRIDADE DO AUTOR DO CÓDIGO FONTE:
A licença pode restringir o código fonte de ser distribuído em uma forma modificada apenas se a licença permitir a distribuição de arquivos patch (de atualização) com o código fonte para o propósito de modificar o programa no momento de sua construção. A licença deve explicitamente permitir a distribuição do programa construído a partir do código fonte modificado. Contudo, a licença pode ainda requerer que programas derivados tenham um nome ou número de versão diferentes do programa original.
NÃO DISCRIMINAÇÃO CONTRA PESSOAS OU GRUPOS:
A licença não pode ser discriminatória contra qualquer pessoa ou grupo de pessoas.
NÃO DISCRIMINAÇÃO CONTRA ÁREAS DE ATUAÇÃO:
A licença não deve restringir qualquer pessoa de usar o programa em um ramo específico de atuação. Por exemplo, ela não deve proibir que o programa seja usado em uma empresa, ou de ser usado para pesquisa genética.
DISTRIBUIÇÃO DA LICENÇA:
Os direitos associados ao programa devem ser aplicáveis para todos aqueles cujo o programa é redistribuído, sem a necessidade da execução de uma licença adicional para estas partes.
LICENÇA NÃO ESPECÍFICA A UM PRODUTO:
Os direitos associados ao programa não devem depender que o programa seja parte de uma distribuição específica de programas. Se o programa é extraído desta distribuição e usado ou distribuído dentro dos termos da licença do programa, todas as partes para quem o programa é redistribuído devem ter os mesmos direitos que aqueles que são garantidos em conjunção com a distribuição de programas original.
LICENÇA NÃO RESTRINJA OUTROS PROGRAMAS:
A licença não pode colocar restrições em outros programas que são distribuídos juntos com o programa licenciado. Isto é, a licença não pode especificar que todos os programas distribuídos na mesma mídia de armazenamento sejam programas de código aberto.
LICENÇA NEUTRA EM RELAÇÃO A TECNOLOGIA:
Nenhuma cláusula da licença pode estabelecer uma tecnologia individual, estilo ou interface a ser aplicada no programa.
SOFTWARE PROPRIETÁRIO:
O software proprietário, privativo ou não livre é um software para computadores que é licenciado com direitos exclusivos para o produtor. Conforme o local de comercialização do software este pode ser abrangido por patentes, direitos de autor assim como limitações para a sua exportação e uso em países terceiros. Seu uso, redistribuição ou modificação é proibido, ou requer que você peça permissão, ou é restrito de tal forma que você não possa efetivamente fazê-lo livremente. A expressão foi criada em oposição ao conceito de software livre.
Existe uma controvérsia entre os benefícios do software livre versus o software proprietário. O primeiro goza da possibilidade de ser modificado pela comunidade ou pelo próprio usuário, enquanto que o segundo oferece um suporte técnico para o cliente. No primeiro caso é óbvia sua redistribuição gratuita, já no segundo, o pagamento pode garantir uma evolução e atualizações no benefício do usuário.
HISTÓRIA:
No final dos anos 1960, os computadores caros e com enormes estruturas, normalmente localizados em grandes quartos com ar condicionado deixaram de ser disponibilizados para locação para começarem a ser vendidos. Os serviços e softwares disponíveis eram geralmente fornecidos pelas fabricantes, sem cobranças separadas, até 1969. O código-fonte do software geralmente era fornecido com o hardware. Usuários que desenvolviam software muitas vezes disponibilizavam-no, sem custos extras. Quem comprava a enorme e cara estrutura (o hardware) não pagava separadamente pelo software.
Em 1969, a IBM, sob a ameaça de litígio Antitruste, levou uma mudança de indústria, começando a cobrar separadamente por softwares e serviços, e deixando de fornecer o código-fonte.
LIMITAÇÕES AO USO:
Normalmente, a fim de que se possa utilizar, copiar, ter acesso ao código-fonte ou redistribuir, deve-se solicitar permissão ao proprietário, ou pagar para poder fazê-lo: será necessário, portanto, adquirir uma licença.
VANTAGENS:
- Maior facilidade de implementação e utilização;
- Possui suporte técnico do fornecedor.
DESVANTAGENS:
- Custo de aquisição normalmente é elevado;
- Quando uma versão nova é lançada é necessário fazer a aquisição da versão nova.
- OBJETIVOS:
Os objetivos deste trabalho é discorrer sobre o tema Business Inteligence (Inteligencia de Negócio) e apresentar os prós e os contras de ferramentas livres e proprietárias para trabalhar com o BI nas organizações.
- OBJETIVOS GERAIS:
Apresentar conceitos de Business Inteligence, falar sobre duas ferramentas utilizadas em BI sendo uma proprietária e outra Open Source e apresentar as principais características de cada uma delas. O porquê de usar cada uma, quais os pontos positivos e os negativos. Comparação entre as ferramentas, o que cada uma pode oferecer, quais as principais razões para utilização de uma ou de outra ferramenta.
- OBJETIVOS ESPECÍFICOS:
Apresentar conceitos de Business Inteligence e falar de pelo menos duas ferramentas de BI, sendo uma proprietária e outra Open Source.
O estudo realizado tem por finalidade apresentar as principais diferenças e semelhanças entre as ferramentas de BI livre e proprietária e principalmente, fazer com que o leitor perceba qual a melhor ferramenta para a realidade da sua empresa.
- JUSTIFICATIVA:
O atual momento de competitividade que vemos nas empresas é algo que tem chamado a atenção de gestores, o fato de poder tomar as decisões certas e prever o caminho que as empresas devem seguir para continuar fortes e de forma crescente tem motivado a alta gestão a adotar sistemas cada vez mais robustos e que suportem estas decisões. Os sistemas de BI caem como uma luva para a estratégia da empresa porque permite a alta gestão planejar o futuro sem necessariamente correr tantos riscos.
Podemos dizer que neste quesito, o BI faz parte da estratégia das organizações pois é também através dele que a empresa será conduzida, é claro que a análise dos gestores e o seu conhecimento de mercado vai agregar maior valor a decisão que será tomada diante das informações disponibilizadas.
Por este motivo, a decisão de implantar estas ferramentas de BI é algo que deve ser pensado e analisado em conjunto com a estratégia da empresa, pois vai influenciar diretamente nas decisões que esta área tomará em relação a organização.
- REVISÃO DE LITERATURA:
O conhecido termo Business Inteligence patenteado pela empresa Gartner, apesar de parecer algo novo, não é tão recente assim. Pelo menos a ideia em seu conceito prático é bem antiga. Podemos observar quando estudamos algumas civilizações antigas que elas em muitos momentos aplicavam princípios de BI, para conseguir informações privilegiadas.
Exemplos disso era quando cruzavam informações analisando tempos de chuvas, comportamento das marés, posições dos astros, etc. É claro que não podemos dizer que isso era o BI que temos tão presentes hoje nas organizações, mas os princípios eram os mesmos. A busca por informações privilegiadas sempre foi algo que podia determinar a sobrevivência de civilizações e no nosso caso, pode determinar a sobrevivência das empresas em um mercado cada vez mais competitivo e exigente.
Com o passar dos anos as empresas passaram a buscar mais estas informações privilegiadas pois viam que através delas, poderiam prever crises, descobrir comportamentos de clientes, se antecipar a situações adversas e por fim, tirar vantagem do uso dessas informações para assim, poder agir antes da concorrência.
De acordo com PONCHIROLLI (2005), “informação é poder”. Ele afirma:
(...) estamos no limiar de uma nova era, na qual o conhecimento é reconhecido como o principal ativo das organizações e a chave para uma vantagem competitiva sustentável. Até então fortemente caracterizada pelos bens tangíveis, como o capital financeiro e as estruturas físicas, a fonte de riqueza e competitividade passa a ser, agora, o próprio conhecimento. Sociedade do conhecimento, era do conhecimento, era do capital intelectual, sociedade pós-capitalista são algumas denominações para esta nova época. PONCHIROLLI (2005).
Entretanto, o autor faz a seguinte advertência sobre o acréscimo de informações:
A quantidade e disponibilidade das informações crescem numa progressão exponencial, confundindo as pessoas e dificultando, sobremodo, a gestão do conhecimento. Sabe-se que tanto a escassez quanto o excesso podem ser prejudiciais: perder-se em uma quantidade incontrolável de informações é tão nocivo como não possuí-las. Temos de aprender a jogar fora, em vez de adorar e acumular informações. Temos de adotar a máxima quanto menos melhor. PONCHIROLLI (2005).
Ainda para PONCHIROLLI (2005), conhecimento é informação internalizada pela pesquisa, estudo ou experiência que tem valor para a organização.
Podemos dizer que a empresa que tem mais informações sobre o mercado, sobre o comportamento dos clientes e sobre as tendências da economia tem maior capacidade de tomar decisão de forma sábia, inteligente e pode fazer projeções que sejam mais acertadas para o sucesso da organização.
“Business Intelligence” é um conjunto de ferramentas de processo contínuo e sistemático que produz conhecimento e perspicácias para uma companhia. Efetivamente, o “Business Intelligence” aumenta a qualidade do planejamento estratégico e operacional e reduz o tempo para a tomada de decisões [BAR2001].
Diante da necessidade de informações cada vez mais rápida e confiável, cresce assustadoramente o uso de sistemas computacionais para dar apoio a todo este processo de coleta, análise e disponibilização da informação. Com este cenário restam algumas questões a serem analisadas pelas organizações: A primeira é como usar a tecnologia como um apoio para fazer dela um fator de sucesso na área estratégica da organização? Como tratar e analisar toda a massa de informação que será armazenado nos bancos de dados da empresa? Como trabalhar esta informação a ponto de ela ser um diferencial para o sucesso da organização? Como transformar tudo isso em vantagem competitiva?
As questões acima são muito debatidas pela área estratégica das organizações e muitas delas investem pesado pois acreditam que o futuro da empresa está diretamente ligado a estes pontos tão importantes para a sobrevivência das mesmas.
Podemos ver que PENNA (2003) dar a entender que informação e, sobretudo, o conhecimento habilitado pelo bom uso da informação, tem papel preponderante na tomada de decisão tanto tática quanto estratégica.
Neste caso, a maneira como vamos trabalhar a informações e as ferramentas que iremos utilizar podem definir o sucesso ou o fracasso da nossa empresa.
Segundo Eckerson (2003) os dados abaixo mostram os resultados de uma pesquisa entre 510 corporações que indicam os benefícios do BI de acordo com a visão dos participantes:
- Economida de Tempo – 61%
- Versão única da verdade 59%
- Melhores estratégias e planos 57%
- Melhores decisões táticas 56%
- Processos mais eficientes 55%
- Economia de custos 37%
Thompson (2004) relatou, a partir de uma survey, que os maiores benefícios do BI são:
- Geração de relatórios mais rápida e precisa 81%
- Melhor tomada de decisões 78%
- Melhor serviço ao cliente 56%
- Maior receita 49%
- FERRAMENTAS DE BUSSINESS INTELLIGENCE
DEFINIÇÃO DE B.I.
Inteligência de negócios (ou Business Intelligence, em inglês) refere-se ao processo de coleta, organização, análise, compartilhamento e monitoramento de informações que oferecem suporte a gestão de negócios. É um conjunto de técnicas e ferramentas para auxiliar na transformação de dados brutos em informações significativas e uteis a fim de analisar o negócio. As tecnologias BI são capazes de suportar uma grande quantidade de dados desestruturados para ajudar a identificar, desenvolver e até mesmo criar uma nova oportunidade de estratégia de negócios. O objetivo do BI é permitir uma fácil interpretação do grande volume de dados. Identificando novas oportunidades e implementando uma estratégia efetiva baseada nos dados, também pode promover negócios com vantagem competitiva no mercado e estabilidade a longo prazo.
ORACLE BUSSINESS INTELIGENCE:
PONTOS POSITIVOS:
- Em comparação as concorrentes, a ferramenta suporta o maior número usuários, o maior volume de dados, a mais ampla variedade de funcionalidades e a maior capacidade de carga de trabalho analítica;
- Plataforma de BI presente no maior número de organizações;
- Integração com outros aplicativos organizacionais;
- Possui um dos maiores canais de venda, procura agregar valor constantemente com sua capacidade de integração entre sistemas.
PONTOS NEGATIVOS:
- Falta de inovação no que envolve dispositivos móveis, memória interna e visualização interativa;
- Qualidade no suporte ao cliente em ligeiro declínio;
- Apesar de investimentos feitos em habilidades de data mining e tecnologias analíticas preditivas, suas aceitações estão abaixo da média se comparado aos concorrentes.
PENTAHO
PONTOS POSITIVOS:
- Gestão e distribuição de informes e painel de controle sobre plataforma de código aberto:
- Otimização do intercâmbio de informação e a colaboração;
- Fácil integração com diferentes fontes de dados e aplicativos que utilizem padrões abertos;
- Totalmente personalizável. Capacidade de usar APIs, serviços web, modificar planilhas, regras de negócios e inclusive o código fonte;
- Flexibilidade nas opções de saída, podendo ser: Adobe PDF, HTML, Microsoft Excel, texto plano, etc;
- Roda em multi-plataformas: Windows, Linux, Macintosh, Unix, etc.
PONTOS NEGATIVOS:
- Documentação fraca;
- Necessidade de conhecimento técnico elevado.
- CONCLUSÃO
Após várias leituras e pesquisas em materiais diversos aliada a observação em empresas que utilizam o BI como fator que as diferenciam das demais nos diversos ramos de atuação, concluímos que a melhor ferramenta de BI é aquela que se adéqua a estrutura, objetivos e condições da empresa.
Como foi falado, a empresa deverá antes de iniciar um processo de implantação do BI e bem antes de definir as ferramentas utilizadas, fazer um estudo profundo de sua estrutura, analisar os objetivos, até que ponto o BI vai ser utilizado e como irá agregar valor a organização e também realizar um estudo de viabilidade detalhado, levando em conta os prós e os contras entre as diversas ferramentas não somente olhando o atual, mas pensando no futuro. Que ferramentas poderá me dar maior suporte daqui a dez anos ou que vantagem terei se adotar esta ferramenta a longo prazo?
Estas são questões que deverão ser discutidas amplamente pela alta gestão da empresa pois fará toda a diferença no futuro.
- BIBLIOGRAFIA:
[BAR2001] BARBIERI, C. BI – Business Intelligence - Modelagem e
Tecnologia. Rio de Janeiro: Axcel Books do Brasil, 2001.
ECKERSON, W. Smart Companies in the 21 st Century: the secrets of creating
successful business intelligent solutions. Seattle, WA: The Data Warehousing
Institute, 2003.
PENNA, Rogerio Adriano Castelpogii, REIS JUNIOR, Alderico Sales dos. O Data Warehouse como Suporte à Inteligência de Negócio. VI SIMPOI - Simpósio de Administração da Produção, Logística e Operações Internacionais. São Paulo, 2003.
PONCHIROLLI, O., FIALHO, Francisco Antonio P. Gestão estratégica do conhecimento como parte da estratégia empresarial. Revista FAE, Curitiba, v. 8, n. 1, pp. 127-138, 2005.
THOMPSON, O. Business intelligence success, lesson learned. Technology Evaluation, 2010.
Publicado em
Banco de Dados
Sexta, 04 Novembro 2016 21:14
Projeto Banco de Dados

O Sistema Controle de Estoque terá como objetivo automatizar e facilitar o controle de entrada e saída de produtos no estoque em um órgão público e efetuara a inclusão, alteração, consulta e remoção de registros nos cadastros de fornecedores, departamentos, produtos, classificação, unidade, movimentação de entrada e saída de produtos. No cadastro de FORNECEDOR será informado os seguintes campos: Código, CNPJ, Razão Social, Nome Fantasia e Endereço que será composto por Rua ou Avenida, Bairro, Cidade, UF e CEP, o cadastro deverá permitir que o fornecedor informe um ou vários telefones, será informado também seu E-mail e URL. Um fornecedor pode suprir o órgão com um ou vários produtos. Será necessário identificar todos os DEPARTAMENTOS que usam produtos do almoxarifado e seu cadastro deverá conter os seguintes campos: Código, Descrição, Responsável, Sala, Rua, Bairro, CEP, Cidade, UF, CEP, Telefone, Contato, Observação.
O PRODUTO é descrito por: Código, Nome do Produto, Descrição, Saldo, Estoque Mínimo, Maximo e Valor Unitário. O produto deverá conter uma classificação e uma unidade. É necessário saber o saldo do produto no estoque que será atualizado sempre que houver a movimentação de entrada e saída do produto.
A CLASSIFICAÇÃO é descrita por Codigo e Descrição.
A UNIDADE é descrita por Codigo e Descrição.
A ENTRADA do Produto será descrita por: Numero da nota fiscal, Código do fornecedor, Data da entrada, Número do empenho, Data da emissão e total da nota fiscal. Cada entrada deverá conter um ou vários produtos que será descrito por Código do produto, Valor unitário, Quantidade, valor Total. A entrada deverá atualizar o saldo do estoque adicionando a quantidade de entrada no cadastro de produtos e informar o valor unitário do produto.
A SAIDA de Produto deverá ser descrita por: Numero da requisição, Data, Código do departamento. A saída deverá permitir a informação de um ou vários produtos que será descrito por código material e quantidade. A saída deverá atualizar o saldo do estoque subtraindo a quantidade de entrada no cadastro de produtos.
Publicado em
Banco de Dados
Quinta, 15 Setembro 2016 17:32
Erro de Instalação no PostgreSQL

Olá pessoal! ao tentar instalar o postgresql-9.5.2-1-windows-x64.exe eu deparei com o seguinte erro no inicio da instalação:
There has been an error.
Un able to write inside TEMP envoronment variable path.
Depois de efetuar algumas pesquisas segui alguns conselhos e verifiquei que o erro ocorreu devido a associação dos arquivos .vbs a algum aplicativo que não seria o padrão.
Efetuei algumas alterações sem sucesso, então verifiquei em uma outra instalação do Windows o registro e constatei o valor padrão que constava na instalação limpa, Para alterar esse valor você precisa ir para HKEY_CLASSES_ROOT\.vbs e definir de volta o (Default) de entrada, clique com o botão direito do Mouse, selecione Modificar... e substitua o campo "Dados do valor" : por VBSFile .

Publicado em
Banco de Dados
Quinta, 15 Setembro 2016 16:39
Normalização e Suas Formas Normais
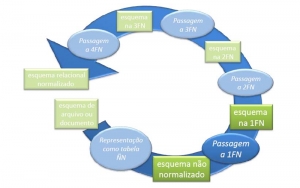
RESUMO
Normalização de dados é o processo formal passo a passo que examina os atributos de uma entidade, com o objetivo de evitar anomalias observadas na inclusão, exclusão e alteração de registros. Uma regra de ouro que devemos observar quando do projeto de um Banco de Dados baseado no Modelo Relacional de Dados é a de "não misturar assuntos em uma mesma Tabela". Por exemplo: na Tabela Clientes devemos colocar somente campos relacionados com o assunto Clientes. Não devemos misturar campos relacionados com outros assuntos, tais como Pedidos, Produtos, etc. Essa "Mistura de Assuntos" em uma mesma tabela acaba por gerar repetição desnecessária dos dados bem como inconsistência dos dados.
1.INTRODUÇÃO
O processo de normalização pode ser visto como o processo no qual são eliminados esquemas de relações (tabelas) não satisfatórios, e compondo-os, através da separação de seus atributos em esquemas de relações menos complexas, mas que satisfaçam as propriedades desejadas.
1.1 Normalização
Por que Normalizar ?
1º) Minimizar de redundâncias e inconsistências;
2º) Facilitar manipulações do Banco de Dados;
3º) Facilitar manutenção do Sistema de Informações
O processo de normalização como foi proposto inicialmente por Edgar Frank Codd.
Para que se compreenda melhor suponha que haja uma entidade PROJETO que armazene as informações dos projetos e funcionários de uma empresa e que o resultado físico final seja a tabela mostrada abaixo.

Ao se observar a tabela vê-se que ela sofre varias anomalias:
Para poder resolver o dilema acima é necessário NORMALIZAR a entidade. Para isto aplicam-se as formas normais como será mostrado a seguir:
2.DESENVOLVIMENTO
2.1 Primeira Forma Normal (1FN)
Uma relação está na 1FN se todos os domínios básicos contiverem valores únicos (não contiver grupos repetitivos). Para atingir esta forma normal é necessário eliminar as redundâncias da base (tautologia) e os grupos de repetição. Isso significa dizer que todos os atributos de uma tabela devem ser atômicos (indivisíveis), ou seja, não são permitidos atributos multivalorados, atributos compostos ou, ainda, atributos multivalorados compostos.
a) Identificar qual elemento é, potencialmente, a chave primária da entidade;
b) Identificar o grupo repetitivo e excluí-lo da entidade;
c) Criar uma nova entidade com a chave primária da entidade anterior e o grupo repetitivo.
A chave primária da nova entidade será obtida pela concatenação da chave primária da entidade inicial e a do grupo repetitivo.
Ex. Não Normalizada

Arquivo de Projetos (CodProjetos, TipoProjeto, Descrição, Matricula, Nome, Categoria, TipoSalario, data, Tempo)
O resultado após a aplicação da primeira forma normal (1FN) será:

Considerando-se, agora, as entidades:
Arquivo de Projetos (CodProjetos, TipoProjeto, Descrição, Matricula, Nome, Categoria, TipoSalario, data, Tempo)
Arquivo de Equipe (CodProjetos,Matricula, Nome, Categoria, Tiposalario, Data, Tempo)
2.2 Segunda Forma Normal (2FN)
Uma relação R está na 2FN se e somente se ela estiver na primeira e todos os atributos não chave forem totalmente dependentes da chave primária (dependente de toda a chave e não apenas de parte dela).
Procedimentos:
a) Identificar os atributos que não são funcionalmente dependentes de toda a chave primária.
b) Remover da entidade todos esses atributos identificados e criar uma nova entidade com eles.
A chave primária da nova entidade será o atributo do qual os atributos do qual os atributos removidos são funcionalmente dependentes.
Considerando-se, agora, a entidade:
Arquivo de Equipes (CodProjetos, Matricula, Nome, Categoria, Tiposalario, Data, Tempo)

O resultado após a aplicação da segunda forma normal (2FN) será:
Arquivo de Equipe (CodProjetos,Matricula, Data, Tempo)
Arquivo de Funcionario (Matricula, Nome, Categoria, Tiposalario)
2.3 Terceira Forma Normal (3FN)
Uma relação R está na 3FN se somente estiver na 2FN e todos os atributos não chave forem dependentes não transitivos da chave primária (cada atributo for funcionalmente dependente apenas dos atributos componentes da chave primária ou se todos os seus atributos não chave forem independentes entre si).
Procedimentos:
a) Identificar todos os atributos que são funcionalmente dependentes de outros atributos não chave;
b) Remove-los e criar uma nova entidade com os mesmos. A chave primária da nova entidade será o atributo do qual os atributos removidos são funcionalmente dependentes.
Considerando-se, agora, as entidades:
Arquivo de Equipes (CodProjetos,Matricula, Data, Tempo)
Arquivo de Funcionario (Matricula, Nome, Categoria, Tiposalario)

O resultado após a aplicação da Terceira forma normal (3FN) será:

Arquivo de Categoria (CodCategoria, Descricao)
Arquivo de TipoSalario (CodTipoSalario, Descricao,Valor, DataInicio)
Arquivo de TipoProjeto (CodTipoProjeto, Descricao)
3. CONCLUSÃO
Podemos perceber que normalmente após a aplicação das regras de normalização de dados, algumas tabelas acabaram sendo divididas em duas ou mais tabelas, o que no final gera um número maior de tabelas do que o originalmente existente. Este processo causa a simplificação dos atributos de uma tabela, colaborando significativamente para a estabilidade do modelo de dados, reduzindo-se consideravelmente as necessidades de manutenção.
Publicado em
Banco de Dados
Terça, 13 Setembro 2016 17:15
Arquitetura de banco de dados
Introdução
Atualmente, devem-se considerar alguns aspectos relevantes para atingir a eficiência e a eficácia dos sistemas informatizados desenvolvidos, a fim de atender seus usuários nos mais variados domínios de aplicação: automação de escritórios, sistemas de apoio a decisões, controle de reserva de recursos, controle e planejamento de produção, alocação e estoque de recursos, entre outros. Tais aspectos são:
Os projetos Lógicos e Funcionais do Banco de Dados devem ser capazes de prever o volume de informações armazenadas a curto, médio e longo prazo. Os projetos devem ter uma grande capacidade de adaptação para os três casos mencionados;
Deve-se ter generalidade e alto grau de abstração de dados, possibilitando confiabilidade e eficiência no armazenamento dos dados e permitindo a utilização de diferentes tipos de gerenciadores de dados através de linguagens de consultas padronizadas;
Projeto de uma interface ágil e com uma "rampa ascendente" para propiciar aprendizado suave ao usuário, no intuito de minimizar o esforço cognitvo;
Implementação de um projeto de interface compatível com múltiplas plataformas (UNIX, Windows NT, Windows Workgroup, etc);
Independência de Implementação da Interface em relação aos SGBDs que darão condições às operações de armazenamento de informações (ORACLE, SYSBASE, INFORMIX, PADRÃO XBASE, etc).
Conversão e mapeamento da diferença semântica entre os paradigmas utilizados no desenvolvimento de interfaces (Imperativo (ou procedural), Orientado a Objeto, Orientado a evento), servidores de dados (Relacional) e programação dos aplicativos (Imperativo, Orientado a Objetos).
Arquiteturas
As primeiras arquiteturas usavam mainframes para executar o processamento principal e de todas as funções do sistema, incluindo os programas aplicativos, programas de interface com o usuário, bem como a funcionalidade dos SGBDs. Esta é a razão pela qual a maioria dos usuários fazia acesso aos sistemas via terminais que não possuíam poder de processamento, apenas a capacidade de visualização. Todos os processamentos eram feitos remotamente, apenas as informações a serem visualizadas e os controles eram enviados do mainframe para os terminais de visualização, conectados a ele por redes de comunicação. Como os preços do hardware foram decrescendo, muitos usuários trocaram seus terminais por computadores pessoais (PC) e estações de trabalho. No começo os SGBDs usavam esses computadores da mesma maneira que usavam os terminais, ou seja, o SGBD era centralizado e toda sua funcionalidade, execução de programas aplicativos e processamento da interface do usuário eram executados em apenas uma máquina. Gradualmente, os SGBDs começaram a explorar a disponibilidade do poder de processamento no lado do usuário, o que levou à arquitetura cliente-servidor.
A arquitetura cliente-servidor foi desenvolvida para dividir ambientes de computação onde um grande número de PCs, estações de trabalho, servidores de arquivos, impressoras, servidores de banco de dados e outros equipamentos são conectados juntos por uma rede. A idéia é definir servidores especializados, tais como servidor de arquivos, que mantém os arquivos de máquinas clientes, ou servidores de impressão que podem estar conectados a várias impressoras; assim, quando se desejar imprimir algo, todas as requisições de impressão são enviadas a este servidor. As máquinas clientes disponibilizam para o usuário as interfaces apropriadas para utilizar esses servidores, bem como poder de processamento para executar aplicações locais. Esta arquitetura se tornou muito popular por algumas razões. Primeiro, a facilidade de implementação dada à clara separação das funcionalidades e dos servidores. Segundo, um servidor é inteligentemente utilizado porque as tarefas mais simples são delegadas às máquinas clientes mais baratas. Terceiro, o usuário pode executar uma interface gráfica que lhe é familiar, ao invés de usar a interface do servidor. Desta maneira, a arquitetura cliente-servidor foi incorporada aos SGBDs comerciais. Diferentes técnicas foram propostas para se implementar essa arquitetura, sendo que a mais adotada pelos Sistemas Gerenciadores de Banco de Dados Relacionais (SGBDRs) comerciais é a inclusão da funcionalidade de um SGBD centralizado no lado do servidor. As consultas e a funcionalidade transacional permanecem no servidor, sendo que este é chamado de servidor de consulta ou servidor de transação. É assim que um servidor SQL é fornecido aos clientes. Cada cliente tem que formular suas consultas SQL, prover a interface do usuário e as funções de interface usando uma linguagem de programação. O cliente pode também se referir a um dicionário de dados o qual inclui informações sobre a distribuição dos dados em vários servidores SQL, bem como os módulos para a decomposição de uma consulta global em um número de consultas locais que podem ser executadas em vários sítios. Comumente o servidor SQL também é chamado de back-end machine e o cliente de front-end machine. Como SQL provê uma linguagem padrão para o SGBDRs, esta criou o ponto de divisão lógica entre o cliente e o servidor.
Atualmente, existem várias tendências para arquitetura de Banco de Dados, nas mais diversas direções.
Resumo das arquiteturas de SGBDs
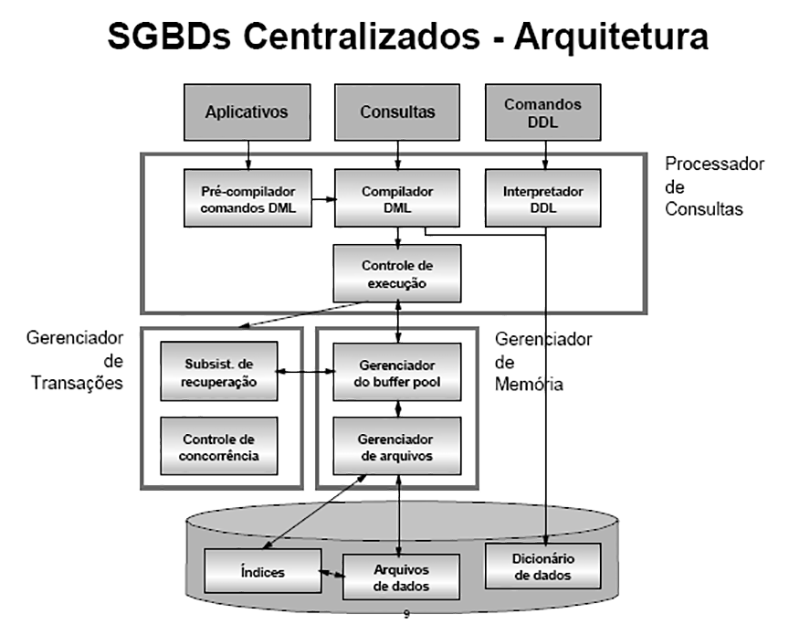
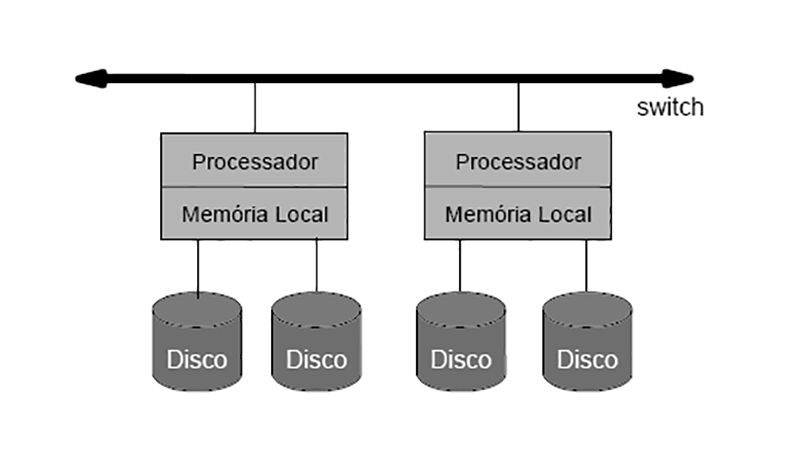
Plataformas centralizadas: Na arquitetura centralizada, existe um computador com grande capacidade de processamento, o qual é o hospedeiro do SGBD e emuladores para os vários aplicativos. Esta arquitetura tem como principal vantagem a de permitir que muitos usuários manipulem grande volume de dados. Sua principal desvantagem está no seu alto custo, pois exige ambiente especial para mainframes e soluções centralizadas.
Sistemas de Computador Pessoal - PC: Os computadores pessoais trabalham em sistema stand-alone, ou seja, fazem seus processamentos sozinhos. No começo esse processamento era bastante limitado, porém, com a evolução do hardware, tem-se hoje PCs com grande capacidade de processamento. Eles utilizam o padrão Xbase e quando se trata de SGBDs, funcionam como hospedeiros e terminais. Desta maneira, possuem um único aplicativo a ser executado na máquina. A principal vantagem desta arquitetura é a simplicidade.
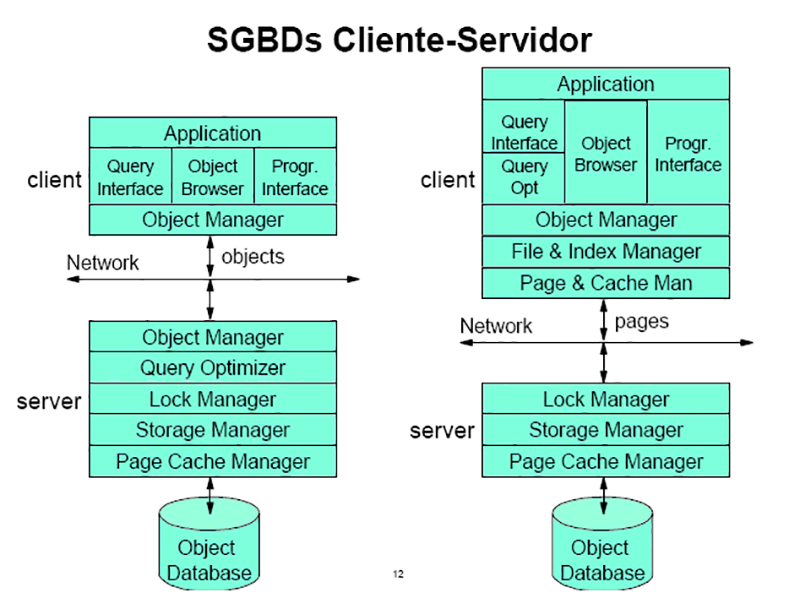
Banco de Dados Cliente-Servidor: Na arquitetura Cliente-Servidor, o cliente (front_end) executa as tarefas do aplicativo, ou seja, fornece a interface do usuário (tela, e processamento de entrada e saída). O servidor (back_end) executa as consultas no DBMS e retorna os resultados ao cliente. Apesar de ser uma arquitetura bastante popular, são necessárias soluções sofisticadas de software que possibilitem: o tratamento de transações, as confirmações de transações (commits), desfazer transações (rollbacks), linguagens de consultas (stored procedures) e gatilhos (triggers). A principal vantagem desta arquitetura é a divisão do processamento entre dois sistemas, o que reduz o tráfego de dados na rede.
SGBDs Paralelos
Combinam técnicas de gerência de dados e processamento paralelo para aumentar desempenho e confiabilidade:
Particionamento do BD em discos controlados por multiprocessadores resulta em aumento da taxa de transferência de dados da memória secundária para memória principal (I/O bandwidth) paralelização do processamento interno de consultas resulta em diminuição do tempo de resposta paralelização do processamento de transações resulta em aumento da capacidade do sistema (throughput)
Banco de dados distribuídos
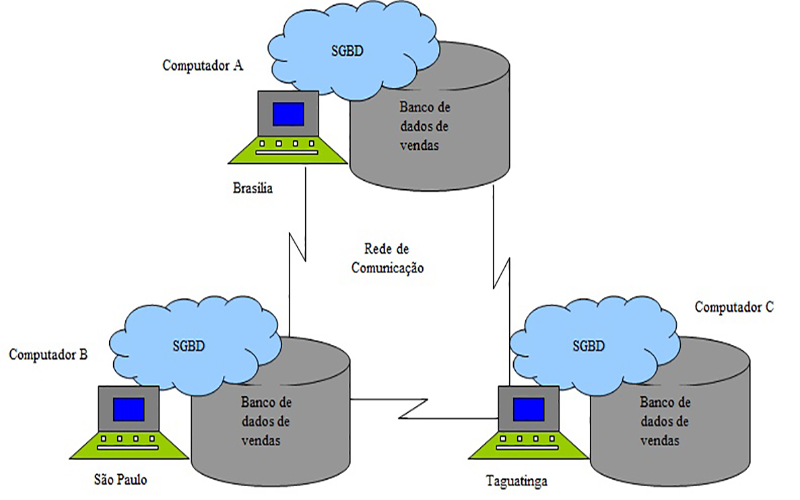
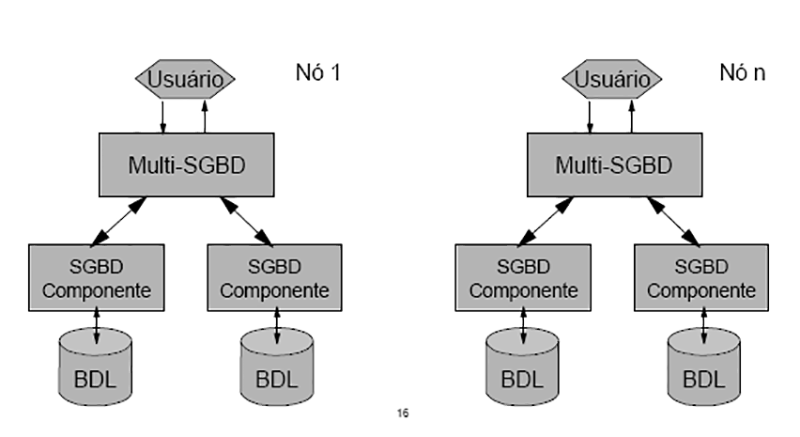
Banco de dados distribuído (BDD) é uma coleção de vários bancos de dados logicamente inter-relacionados, distribuídos por uma rede de computadores. Existem dois tipos de banco de dados distribuídos, os homogêneos e os heterogêneos. Os homogêneos são compostos pelos mesmos bancos de dados, já os Heterogêneos são aqueles que são compostos por mais de um tipo de banco de dados.
Grau de homogeneidade dos softwares do SGBDD
- BDD Homogêneo – Se todos os sítios utilizam softwares idênticos.
- BDD Heterogêneos – Se os sítios utilizam softwares diferentes.
-
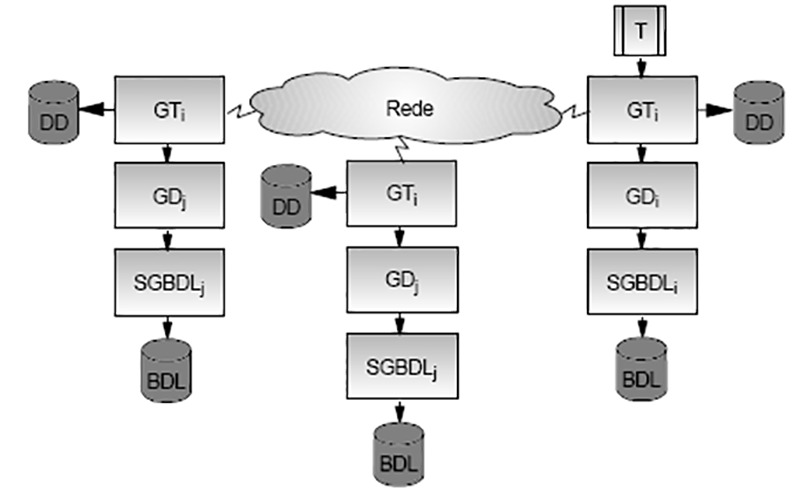
Num banco de dados distribuídos os arquivos podem estar replicados ou fragmentados, esses dois tipos podem ser encontrados aos longos dos nós do sistema de BDD's. Quando os dados se encontram replicados, existe uma cópia de cada um dos dados em cada nó, tornando as bases iguais (ex: tabela de produtos de uma grande loja). Já na fragmentação, os dados se encontram divididos ao longo do sistema, ou seja, a cada nó existe uma base de dados diferente se olharmos de uma forma local, mas se analisarmos de uma forma global os dados são vistos de uma forma única, pois cada nó possui um catálogo que contém cada informação dos dados dos bancos adjacentes.
A replicação dos dados pode se dar de maneira síncrona ou assíncrona. No caso de replicação síncrona, cada transação é dada como concluída quando todos os nós confirmam que a transação local foi bem-sucedida. Na replicação assíncrona, o nó principal executa a transação enviando confirmação ao solicitante e então encaminha a transação aos demais nós.
Arquitetura Básica
-
Usuários acessam banco de dados distribuídos através:
Aplicações Locais
Aplicações que não requerem dados de outros lugares.
Aplicações Globais
Aplicações que requerem dados de outros lugares.
Importantes considerações
- A distribuição é transparente — usuários devem poder interagir com o sistema como se ele fosse um único sistema lógico. Isso se aplica ao desempenho do sistema, métodos de acesso, entre outras coisas.Transações são transparentes — cada transação deve manter a integridade do banco de dados dentre os múltiplos bancos de dados. Transações devem também ser divididas em subtransações, cada subtransação afetando um sistema de banco de dados...
Cuidado com banco de dados distribuídos devem ser tomados para assegurar o seguinte:
Vantagens de bancos de dados distribuídos
Disponibilidade
- – ao contrário da arquitetura centralizada, na arquitetura distribuída a ocorrência de uma falha em um dos sítios não deixa inoperável todo o BD. Alguns dados tornam-se inatingíveis, mas outras partes do BD podem ser acessadas.
Autonomia Local
- — um departamento pode controlar seus dados (já que é o mais familiarizado com estes).
Maior disponibilidade
- — uma falha em um banco de dados afetará somente um fragmento, ao invés do banco de dados inteiro.
Melhor performance
- — os dados estão localizados próximo do local de maior demanda e os sistemas de banco de dados por si só são paralelizáveis, permitindo carregar no banco de dados para o balanceamento entre servidores (a elevada carga em um módulo do banco de dados não irá afetar os outros módulos de banco de dados em um banco de dados distribuído).
Melhor Desempenho
- – quando um grande BD é distribuído em vários sítios, existem BD menores em cada sítio. Por este motivo, consultas e transações que acessam os dados em um único sítio têm melhor desempenho. Além disso, cada sítio tem um número menor de transações em execução do que no caso de todas as transações serem submetidas a um único BD centralizado.
Econômico
- — custa menos criar uma rede de pequenos computadores com o mesmo poder que um único computador maior.
Modularidade
- — sistemas podem ser modificados, adicionados ou removidos do banco de dados distribuído sem afetar os outros módulos (sistemas).
Desvantagens de banco de dados distribuídos
- Autonomia Local — um departamento pode controlar seus dados (já que é o mais familiarizado com estes).Maior disponibilidade — uma falha em um banco de dados afetará somente um fragmento, ao invés do banco de dados inteiro.
Complexidade — trabalho extra deve ser feito pelos DBAs para garantir que a natureza da distribuição do sistema é transparente. Trabalho extra deve ser feito para manter sistemas múltiplos diferentes, ao invés de um único grande. Design de banco de dados extra deve também ser feito para levar em conta a natureza desconectada do banco de dados - por exemplo, joins tornam-se proibitivamente caros quando são rodados entre múltiplas plataformas.
Implantação mais cara — o aumento da complexidade e uma infra-estrutura mais extensa significa custo extra de trabalho
Segurança — fragmentos de banco de dados remotos devem ser seguros e, como eles não são centralizados então os lugares remotos também devem ser seguros. A infra-estrutura também deve ser segura (por exemplo, pela encriptação dos links de rede entre os lugares remotos).
Difícil de manter a integridade — em sistemas distribuídos, reforçar a integridade ao longo de uma rede pode exigir demais dos recursos da rede para ser viável.
Inexperiência — pode ser difícil trabalhar com banco de dados distribuídos e como é uma área relativamente nova ainda não há tantos casos (ou experiências) práticos de seu uso disponíveis como exemplo.
Falta de padrões – ainda não há metodologias e ferramentas para ajudar usuários a converter um SGBD centralizado para um SGBD distribuído.
Design do banco de dados mais complexa – além das dificuldades normais, o design de um banco de dados distribuídos tem que considerar a fragmentação dos dados, alocação dos fragmentos em lugares específicos e a replicação de dados.
SGBDs para Estações Móveis
-
Características:
topologia:
um backbone fixo com estações de controle também fixas conjunto de células nas quais transitam as estações móveis.
localização dos dados:
dados residem tanto nas estações fixas quanto nas móveis ("walkstations")

Manutenção do Diretório:
-
Problema:
Como localizar as estações móveis que contêm os dados desejados Alternativas:
Armazenar a localização da estação móvel apenas na sua estação de base distribuir a informação sobre a localização das estações móveis pre-anunciar o roteiro de cada estação móvel
Caching:
Problema:
Limite da bateria da estação móvel impõe restrições sobre o grau de caching
Alternativas:
Mover consultas para estações fixas, transferindo apenas resultados adotar filtros semânticos mais sofisticados para reduzir o tamanho do cachê.
Publicado em
Banco de Dados