Fortaleza, Quinta-feira, 18 Abril 2024
Tecnologia da Informação
Mostrando itens por tag: Arquitetura de banco de dados
Terça, 13 Setembro 2016 17:15
Arquitetura de banco de dados
Introdução
Atualmente, devem-se considerar alguns aspectos relevantes para atingir a eficiência e a eficácia dos sistemas informatizados desenvolvidos, a fim de atender seus usuários nos mais variados domínios de aplicação: automação de escritórios, sistemas de apoio a decisões, controle de reserva de recursos, controle e planejamento de produção, alocação e estoque de recursos, entre outros. Tais aspectos são:
Os projetos Lógicos e Funcionais do Banco de Dados devem ser capazes de prever o volume de informações armazenadas a curto, médio e longo prazo. Os projetos devem ter uma grande capacidade de adaptação para os três casos mencionados;
Deve-se ter generalidade e alto grau de abstração de dados, possibilitando confiabilidade e eficiência no armazenamento dos dados e permitindo a utilização de diferentes tipos de gerenciadores de dados através de linguagens de consultas padronizadas;
Projeto de uma interface ágil e com uma "rampa ascendente" para propiciar aprendizado suave ao usuário, no intuito de minimizar o esforço cognitvo;
Implementação de um projeto de interface compatível com múltiplas plataformas (UNIX, Windows NT, Windows Workgroup, etc);
Independência de Implementação da Interface em relação aos SGBDs que darão condições às operações de armazenamento de informações (ORACLE, SYSBASE, INFORMIX, PADRÃO XBASE, etc).
Conversão e mapeamento da diferença semântica entre os paradigmas utilizados no desenvolvimento de interfaces (Imperativo (ou procedural), Orientado a Objeto, Orientado a evento), servidores de dados (Relacional) e programação dos aplicativos (Imperativo, Orientado a Objetos).
Arquiteturas
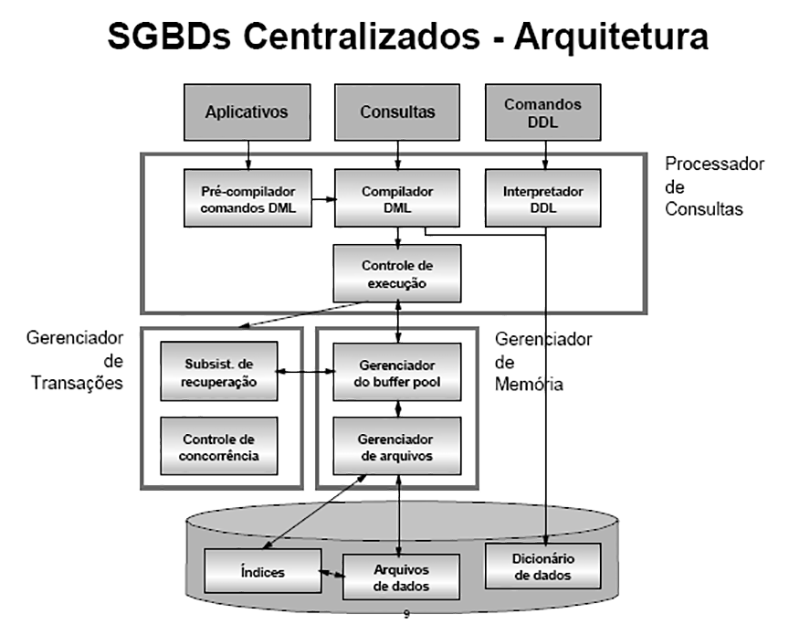
As primeiras arquiteturas usavam mainframes para executar o processamento principal e de todas as funções do sistema, incluindo os programas aplicativos, programas de interface com o usuário, bem como a funcionalidade dos SGBDs. Esta é a razão pela qual a maioria dos usuários fazia acesso aos sistemas via terminais que não possuíam poder de processamento, apenas a capacidade de visualização. Todos os processamentos eram feitos remotamente, apenas as informações a serem visualizadas e os controles eram enviados do mainframe para os terminais de visualização, conectados a ele por redes de comunicação. Como os preços do hardware foram decrescendo, muitos usuários trocaram seus terminais por computadores pessoais (PC) e estações de trabalho. No começo os SGBDs usavam esses computadores da mesma maneira que usavam os terminais, ou seja, o SGBD era centralizado e toda sua funcionalidade, execução de programas aplicativos e processamento da interface do usuário eram executados em apenas uma máquina. Gradualmente, os SGBDs começaram a explorar a disponibilidade do poder de processamento no lado do usuário, o que levou à arquitetura cliente-servidor.
A arquitetura cliente-servidor foi desenvolvida para dividir ambientes de computação onde um grande número de PCs, estações de trabalho, servidores de arquivos, impressoras, servidores de banco de dados e outros equipamentos são conectados juntos por uma rede. A idéia é definir servidores especializados, tais como servidor de arquivos, que mantém os arquivos de máquinas clientes, ou servidores de impressão que podem estar conectados a várias impressoras; assim, quando se desejar imprimir algo, todas as requisições de impressão são enviadas a este servidor. As máquinas clientes disponibilizam para o usuário as interfaces apropriadas para utilizar esses servidores, bem como poder de processamento para executar aplicações locais. Esta arquitetura se tornou muito popular por algumas razões. Primeiro, a facilidade de implementação dada à clara separação das funcionalidades e dos servidores. Segundo, um servidor é inteligentemente utilizado porque as tarefas mais simples são delegadas às máquinas clientes mais baratas. Terceiro, o usuário pode executar uma interface gráfica que lhe é familiar, ao invés de usar a interface do servidor. Desta maneira, a arquitetura cliente-servidor foi incorporada aos SGBDs comerciais. Diferentes técnicas foram propostas para se implementar essa arquitetura, sendo que a mais adotada pelos Sistemas Gerenciadores de Banco de Dados Relacionais (SGBDRs) comerciais é a inclusão da funcionalidade de um SGBD centralizado no lado do servidor. As consultas e a funcionalidade transacional permanecem no servidor, sendo que este é chamado de servidor de consulta ou servidor de transação. É assim que um servidor SQL é fornecido aos clientes. Cada cliente tem que formular suas consultas SQL, prover a interface do usuário e as funções de interface usando uma linguagem de programação. O cliente pode também se referir a um dicionário de dados o qual inclui informações sobre a distribuição dos dados em vários servidores SQL, bem como os módulos para a decomposição de uma consulta global em um número de consultas locais que podem ser executadas em vários sítios. Comumente o servidor SQL também é chamado de back-end machine e o cliente de front-end machine. Como SQL provê uma linguagem padrão para o SGBDRs, esta criou o ponto de divisão lógica entre o cliente e o servidor.
Atualmente, existem várias tendências para arquitetura de Banco de Dados, nas mais diversas direções.
Resumo das arquiteturas de SGBDs
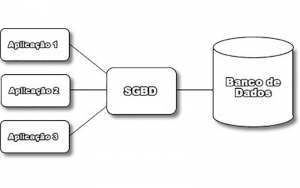
Plataformas centralizadas: Na arquitetura centralizada, existe um computador com grande capacidade de processamento, o qual é o hospedeiro do SGBD e emuladores para os vários aplicativos. Esta arquitetura tem como principal vantagem a de permitir que muitos usuários manipulem grande volume de dados. Sua principal desvantagem está no seu alto custo, pois exige ambiente especial para mainframes e soluções centralizadas.
Sistemas de Computador Pessoal - PC: Os computadores pessoais trabalham em sistema stand-alone, ou seja, fazem seus processamentos sozinhos. No começo esse processamento era bastante limitado, porém, com a evolução do hardware, tem-se hoje PCs com grande capacidade de processamento. Eles utilizam o padrão Xbase e quando se trata de SGBDs, funcionam como hospedeiros e terminais. Desta maneira, possuem um único aplicativo a ser executado na máquina. A principal vantagem desta arquitetura é a simplicidade.
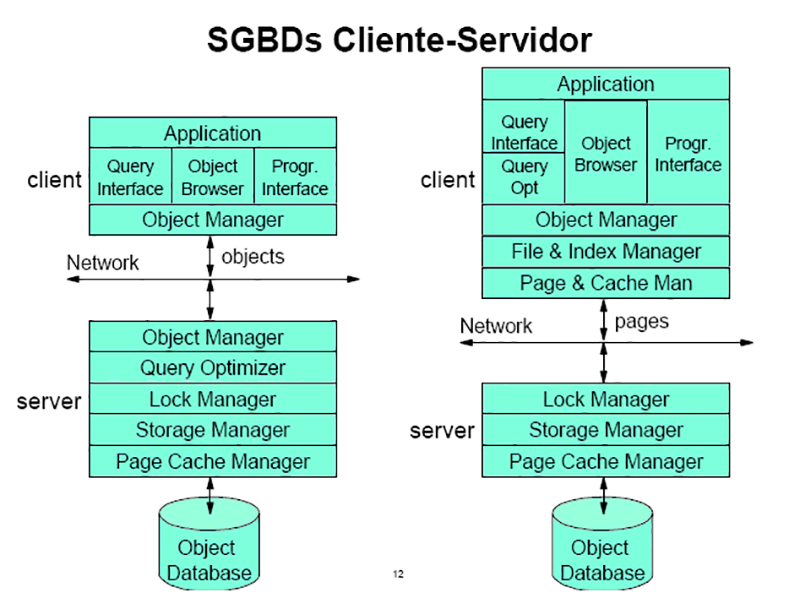
Banco de Dados Cliente-Servidor: Na arquitetura Cliente-Servidor, o cliente (front_end) executa as tarefas do aplicativo, ou seja, fornece a interface do usuário (tela, e processamento de entrada e saída). O servidor (back_end) executa as consultas no DBMS e retorna os resultados ao cliente. Apesar de ser uma arquitetura bastante popular, são necessárias soluções sofisticadas de software que possibilitem: o tratamento de transações, as confirmações de transações (commits), desfazer transações (rollbacks), linguagens de consultas (stored procedures) e gatilhos (triggers). A principal vantagem desta arquitetura é a divisão do processamento entre dois sistemas, o que reduz o tráfego de dados na rede.
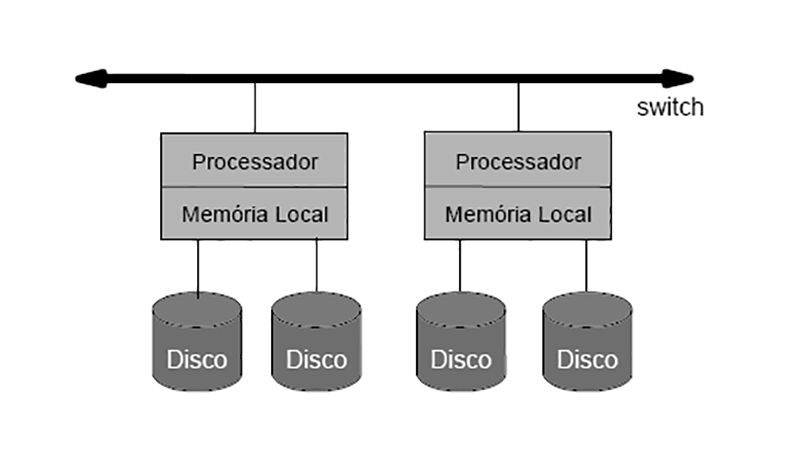
SGBDs Paralelos
Combinam técnicas de gerência de dados e processamento paralelo para aumentar desempenho e confiabilidade:
Particionamento do BD em discos controlados por multiprocessadores resulta em aumento da taxa de transferência de dados da memória secundária para memória principal (I/O bandwidth) paralelização do processamento interno de consultas resulta em diminuição do tempo de resposta paralelização do processamento de transações resulta em aumento da capacidade do sistema (throughput)
Banco de dados distribuídos
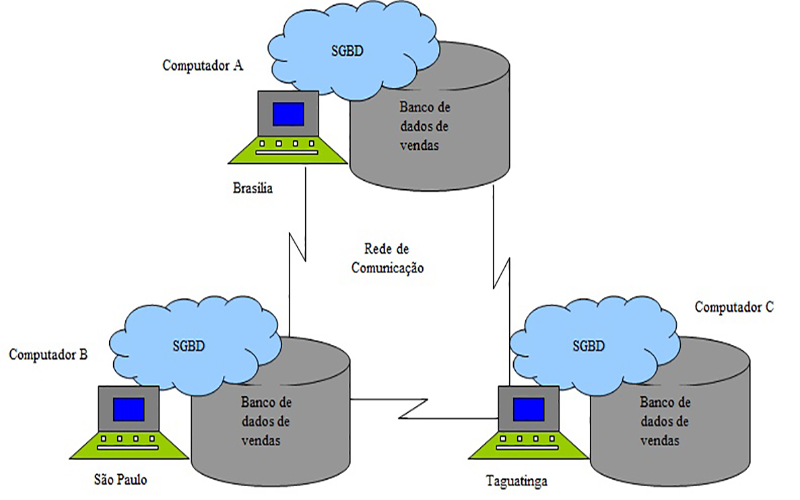
Banco de dados distribuído (BDD) é uma coleção de vários bancos de dados logicamente inter-relacionados, distribuídos por uma rede de computadores. Existem dois tipos de banco de dados distribuídos, os homogêneos e os heterogêneos. Os homogêneos são compostos pelos mesmos bancos de dados, já os Heterogêneos são aqueles que são compostos por mais de um tipo de banco de dados.
Grau de homogeneidade dos softwares do SGBDD
- BDD Homogêneo – Se todos os sítios utilizam softwares idênticos.
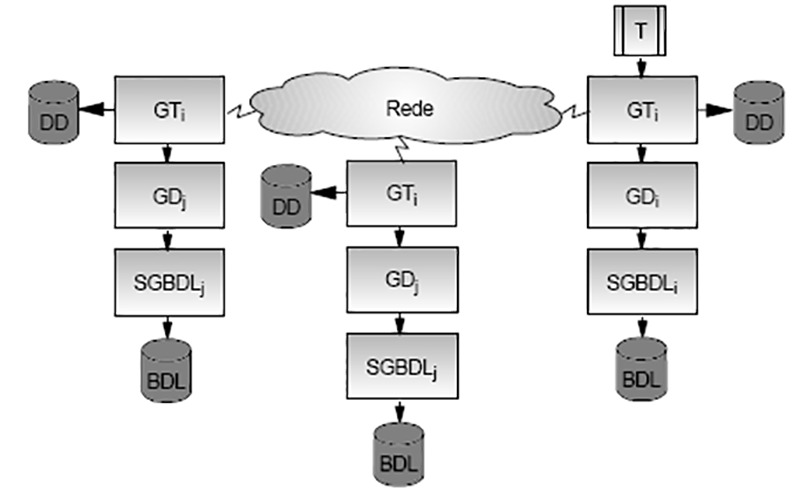
- BDD Heterogêneos – Se os sítios utilizam softwares diferentes.
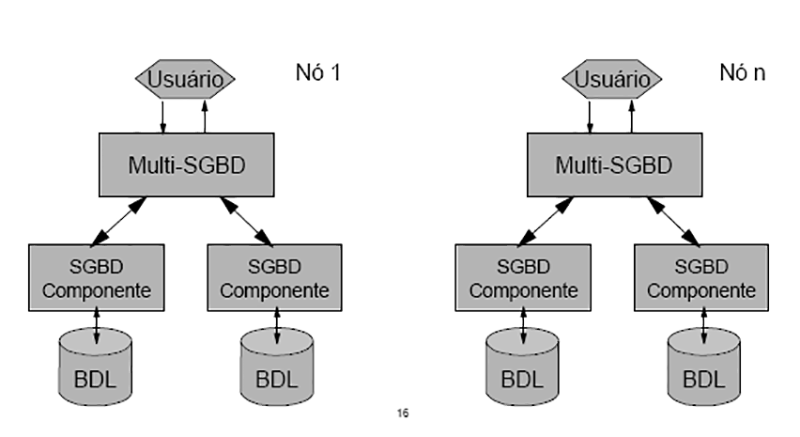
-
Num banco de dados distribuídos os arquivos podem estar replicados ou fragmentados, esses dois tipos podem ser encontrados aos longos dos nós do sistema de BDD's. Quando os dados se encontram replicados, existe uma cópia de cada um dos dados em cada nó, tornando as bases iguais (ex: tabela de produtos de uma grande loja). Já na fragmentação, os dados se encontram divididos ao longo do sistema, ou seja, a cada nó existe uma base de dados diferente se olharmos de uma forma local, mas se analisarmos de uma forma global os dados são vistos de uma forma única, pois cada nó possui um catálogo que contém cada informação dos dados dos bancos adjacentes.
A replicação dos dados pode se dar de maneira síncrona ou assíncrona. No caso de replicação síncrona, cada transação é dada como concluída quando todos os nós confirmam que a transação local foi bem-sucedida. Na replicação assíncrona, o nó principal executa a transação enviando confirmação ao solicitante e então encaminha a transação aos demais nós.
Arquitetura Básica
-
Usuários acessam banco de dados distribuídos através:
Aplicações Locais
Aplicações que não requerem dados de outros lugares.
Aplicações Globais
Aplicações que requerem dados de outros lugares.
Importantes considerações
- A distribuição é transparente — usuários devem poder interagir com o sistema como se ele fosse um único sistema lógico. Isso se aplica ao desempenho do sistema, métodos de acesso, entre outras coisas.Transações são transparentes — cada transação deve manter a integridade do banco de dados dentre os múltiplos bancos de dados. Transações devem também ser divididas em subtransações, cada subtransação afetando um sistema de banco de dados...
Cuidado com banco de dados distribuídos devem ser tomados para assegurar o seguinte:
Vantagens de bancos de dados distribuídos
Disponibilidade
- – ao contrário da arquitetura centralizada, na arquitetura distribuída a ocorrência de uma falha em um dos sítios não deixa inoperável todo o BD. Alguns dados tornam-se inatingíveis, mas outras partes do BD podem ser acessadas.
Autonomia Local
- — um departamento pode controlar seus dados (já que é o mais familiarizado com estes).
Maior disponibilidade
- — uma falha em um banco de dados afetará somente um fragmento, ao invés do banco de dados inteiro.
Melhor performance
- — os dados estão localizados próximo do local de maior demanda e os sistemas de banco de dados por si só são paralelizáveis, permitindo carregar no banco de dados para o balanceamento entre servidores (a elevada carga em um módulo do banco de dados não irá afetar os outros módulos de banco de dados em um banco de dados distribuído).
Melhor Desempenho
- – quando um grande BD é distribuído em vários sítios, existem BD menores em cada sítio. Por este motivo, consultas e transações que acessam os dados em um único sítio têm melhor desempenho. Além disso, cada sítio tem um número menor de transações em execução do que no caso de todas as transações serem submetidas a um único BD centralizado.
Econômico
- — custa menos criar uma rede de pequenos computadores com o mesmo poder que um único computador maior.
Modularidade
- — sistemas podem ser modificados, adicionados ou removidos do banco de dados distribuído sem afetar os outros módulos (sistemas).
Desvantagens de banco de dados distribuídos
- Autonomia Local — um departamento pode controlar seus dados (já que é o mais familiarizado com estes).Maior disponibilidade — uma falha em um banco de dados afetará somente um fragmento, ao invés do banco de dados inteiro.
Complexidade — trabalho extra deve ser feito pelos DBAs para garantir que a natureza da distribuição do sistema é transparente. Trabalho extra deve ser feito para manter sistemas múltiplos diferentes, ao invés de um único grande. Design de banco de dados extra deve também ser feito para levar em conta a natureza desconectada do banco de dados - por exemplo, joins tornam-se proibitivamente caros quando são rodados entre múltiplas plataformas.
Implantação mais cara — o aumento da complexidade e uma infra-estrutura mais extensa significa custo extra de trabalho
Segurança — fragmentos de banco de dados remotos devem ser seguros e, como eles não são centralizados então os lugares remotos também devem ser seguros. A infra-estrutura também deve ser segura (por exemplo, pela encriptação dos links de rede entre os lugares remotos).
Difícil de manter a integridade — em sistemas distribuídos, reforçar a integridade ao longo de uma rede pode exigir demais dos recursos da rede para ser viável.
Inexperiência — pode ser difícil trabalhar com banco de dados distribuídos e como é uma área relativamente nova ainda não há tantos casos (ou experiências) práticos de seu uso disponíveis como exemplo.
Falta de padrões – ainda não há metodologias e ferramentas para ajudar usuários a converter um SGBD centralizado para um SGBD distribuído.
Design do banco de dados mais complexa – além das dificuldades normais, o design de um banco de dados distribuídos tem que considerar a fragmentação dos dados, alocação dos fragmentos em lugares específicos e a replicação de dados.
SGBDs para Estações Móveis
-
Características:
topologia:
um backbone fixo com estações de controle também fixas conjunto de células nas quais transitam as estações móveis.
localização dos dados:
dados residem tanto nas estações fixas quanto nas móveis ("walkstations")

Manutenção do Diretório:
-
Problema:
Como localizar as estações móveis que contêm os dados desejados Alternativas:
Armazenar a localização da estação móvel apenas na sua estação de base distribuir a informação sobre a localização das estações móveis pre-anunciar o roteiro de cada estação móvel
Caching:
Problema:
Limite da bateria da estação móvel impõe restrições sobre o grau de caching
Alternativas:
Mover consultas para estações fixas, transferindo apenas resultados adotar filtros semânticos mais sofisticados para reduzir o tamanho do cachê.
Publicado em
Banco de Dados