Fortaleza, Domingo, 31 Mai 2026
Tecnologia da Informação
Mostrando itens por tag: Postgress
Quinta, 15 Setembro 2016 17:32
Erro de Instalação no PostgreSQL

Olá pessoal! ao tentar instalar o postgresql-9.5.2-1-windows-x64.exe eu deparei com o seguinte erro no inicio da instalação:
There has been an error.
Un able to write inside TEMP envoronment variable path.
Depois de efetuar algumas pesquisas segui alguns conselhos e verifiquei que o erro ocorreu devido a associação dos arquivos .vbs a algum aplicativo que não seria o padrão.
Efetuei algumas alterações sem sucesso, então verifiquei em uma outra instalação do Windows o registro e constatei o valor padrão que constava na instalação limpa, Para alterar esse valor você precisa ir para HKEY_CLASSES_ROOT\.vbs e definir de volta o (Default) de entrada, clique com o botão direito do Mouse, selecione Modificar... e substitua o campo "Dados do valor" : por VBSFile .

Publicado em
Banco de Dados
Terça, 13 Setembro 2016 17:15
Arquitetura de banco de dados
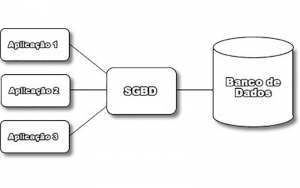
Introdução
Atualmente, devem-se considerar alguns aspectos relevantes para atingir a eficiência e a eficácia dos sistemas informatizados desenvolvidos, a fim de atender seus usuários nos mais variados domínios de aplicação: automação de escritórios, sistemas de apoio a decisões, controle de reserva de recursos, controle e planejamento de produção, alocação e estoque de recursos, entre outros. Tais aspectos são:
Os projetos Lógicos e Funcionais do Banco de Dados devem ser capazes de prever o volume de informações armazenadas a curto, médio e longo prazo. Os projetos devem ter uma grande capacidade de adaptação para os três casos mencionados;
Deve-se ter generalidade e alto grau de abstração de dados, possibilitando confiabilidade e eficiência no armazenamento dos dados e permitindo a utilização de diferentes tipos de gerenciadores de dados através de linguagens de consultas padronizadas;
Projeto de uma interface ágil e com uma "rampa ascendente" para propiciar aprendizado suave ao usuário, no intuito de minimizar o esforço cognitvo;
Implementação de um projeto de interface compatível com múltiplas plataformas (UNIX, Windows NT, Windows Workgroup, etc);
Independência de Implementação da Interface em relação aos SGBDs que darão condições às operações de armazenamento de informações (ORACLE, SYSBASE, INFORMIX, PADRÃO XBASE, etc).
Conversão e mapeamento da diferença semântica entre os paradigmas utilizados no desenvolvimento de interfaces (Imperativo (ou procedural), Orientado a Objeto, Orientado a evento), servidores de dados (Relacional) e programação dos aplicativos (Imperativo, Orientado a Objetos).
Arquiteturas
As primeiras arquiteturas usavam mainframes para executar o processamento principal e de todas as funções do sistema, incluindo os programas aplicativos, programas de interface com o usuário, bem como a funcionalidade dos SGBDs. Esta é a razão pela qual a maioria dos usuários fazia acesso aos sistemas via terminais que não possuíam poder de processamento, apenas a capacidade de visualização. Todos os processamentos eram feitos remotamente, apenas as informações a serem visualizadas e os controles eram enviados do mainframe para os terminais de visualização, conectados a ele por redes de comunicação. Como os preços do hardware foram decrescendo, muitos usuários trocaram seus terminais por computadores pessoais (PC) e estações de trabalho. No começo os SGBDs usavam esses computadores da mesma maneira que usavam os terminais, ou seja, o SGBD era centralizado e toda sua funcionalidade, execução de programas aplicativos e processamento da interface do usuário eram executados em apenas uma máquina. Gradualmente, os SGBDs começaram a explorar a disponibilidade do poder de processamento no lado do usuário, o que levou à arquitetura cliente-servidor.
A arquitetura cliente-servidor foi desenvolvida para dividir ambientes de computação onde um grande número de PCs, estações de trabalho, servidores de arquivos, impressoras, servidores de banco de dados e outros equipamentos são conectados juntos por uma rede. A idéia é definir servidores especializados, tais como servidor de arquivos, que mantém os arquivos de máquinas clientes, ou servidores de impressão que podem estar conectados a várias impressoras; assim, quando se desejar imprimir algo, todas as requisições de impressão são enviadas a este servidor. As máquinas clientes disponibilizam para o usuário as interfaces apropriadas para utilizar esses servidores, bem como poder de processamento para executar aplicações locais. Esta arquitetura se tornou muito popular por algumas razões. Primeiro, a facilidade de implementação dada à clara separação das funcionalidades e dos servidores. Segundo, um servidor é inteligentemente utilizado porque as tarefas mais simples são delegadas às máquinas clientes mais baratas. Terceiro, o usuário pode executar uma interface gráfica que lhe é familiar, ao invés de usar a interface do servidor. Desta maneira, a arquitetura cliente-servidor foi incorporada aos SGBDs comerciais. Diferentes técnicas foram propostas para se implementar essa arquitetura, sendo que a mais adotada pelos Sistemas Gerenciadores de Banco de Dados Relacionais (SGBDRs) comerciais é a inclusão da funcionalidade de um SGBD centralizado no lado do servidor. As consultas e a funcionalidade transacional permanecem no servidor, sendo que este é chamado de servidor de consulta ou servidor de transação. É assim que um servidor SQL é fornecido aos clientes. Cada cliente tem que formular suas consultas SQL, prover a interface do usuário e as funções de interface usando uma linguagem de programação. O cliente pode também se referir a um dicionário de dados o qual inclui informações sobre a distribuição dos dados em vários servidores SQL, bem como os módulos para a decomposição de uma consulta global em um número de consultas locais que podem ser executadas em vários sítios. Comumente o servidor SQL também é chamado de back-end machine e o cliente de front-end machine. Como SQL provê uma linguagem padrão para o SGBDRs, esta criou o ponto de divisão lógica entre o cliente e o servidor.
Atualmente, existem várias tendências para arquitetura de Banco de Dados, nas mais diversas direções.
Resumo das arquiteturas de SGBDs
Plataformas centralizadas: Na arquitetura centralizada, existe um computador com grande capacidade de processamento, o qual é o hospedeiro do SGBD e emuladores para os vários aplicativos. Esta arquitetura tem como principal vantagem a de permitir que muitos usuários manipulem grande volume de dados. Sua principal desvantagem está no seu alto custo, pois exige ambiente especial para mainframes e soluções centralizadas.
Sistemas de Computador Pessoal - PC: Os computadores pessoais trabalham em sistema stand-alone, ou seja, fazem seus processamentos sozinhos. No começo esse processamento era bastante limitado, porém, com a evolução do hardware, tem-se hoje PCs com grande capacidade de processamento. Eles utilizam o padrão Xbase e quando se trata de SGBDs, funcionam como hospedeiros e terminais. Desta maneira, possuem um único aplicativo a ser executado na máquina. A principal vantagem desta arquitetura é a simplicidade.
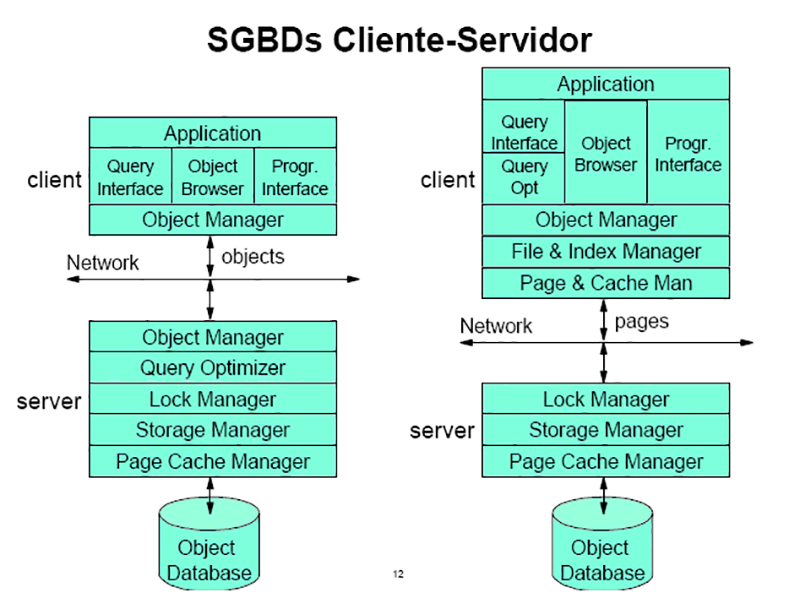
Banco de Dados Cliente-Servidor: Na arquitetura Cliente-Servidor, o cliente (front_end) executa as tarefas do aplicativo, ou seja, fornece a interface do usuário (tela, e processamento de entrada e saída). O servidor (back_end) executa as consultas no DBMS e retorna os resultados ao cliente. Apesar de ser uma arquitetura bastante popular, são necessárias soluções sofisticadas de software que possibilitem: o tratamento de transações, as confirmações de transações (commits), desfazer transações (rollbacks), linguagens de consultas (stored procedures) e gatilhos (triggers). A principal vantagem desta arquitetura é a divisão do processamento entre dois sistemas, o que reduz o tráfego de dados na rede.
SGBDs Paralelos
Combinam técnicas de gerência de dados e processamento paralelo para aumentar desempenho e confiabilidade:
Particionamento do BD em discos controlados por multiprocessadores resulta em aumento da taxa de transferência de dados da memória secundária para memória principal (I/O bandwidth) paralelização do processamento interno de consultas resulta em diminuição do tempo de resposta paralelização do processamento de transações resulta em aumento da capacidade do sistema (throughput)
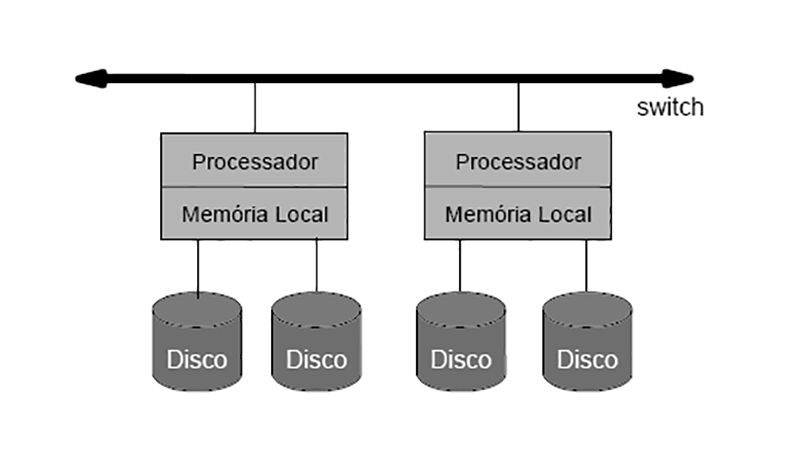
Banco de dados distribuídos
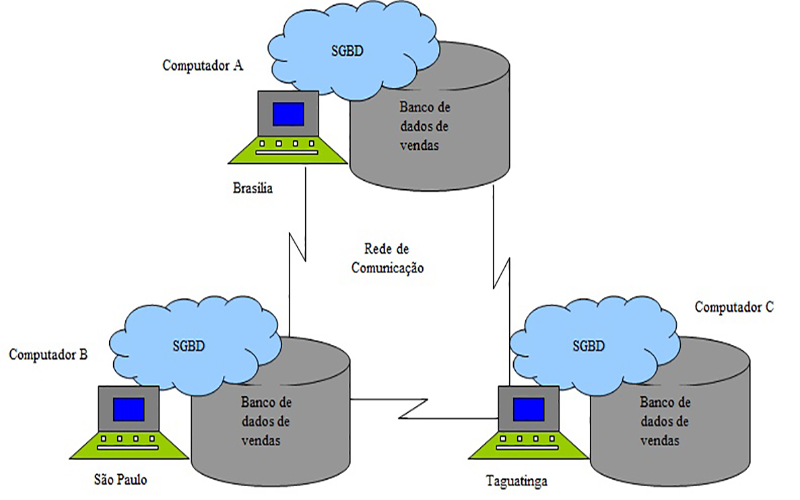
Banco de dados distribuído (BDD) é uma coleção de vários bancos de dados logicamente inter-relacionados, distribuídos por uma rede de computadores. Existem dois tipos de banco de dados distribuídos, os homogêneos e os heterogêneos. Os homogêneos são compostos pelos mesmos bancos de dados, já os Heterogêneos são aqueles que são compostos por mais de um tipo de banco de dados.
Grau de homogeneidade dos softwares do SGBDD
- BDD Homogêneo – Se todos os sítios utilizam softwares idênticos.
- BDD Heterogêneos – Se os sítios utilizam softwares diferentes.
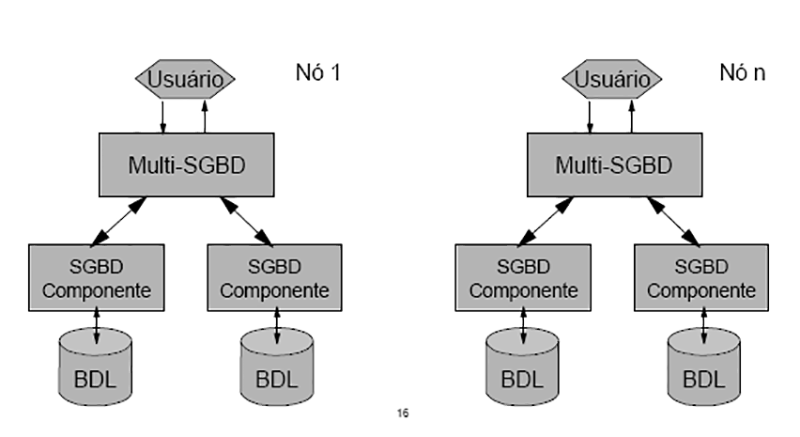
-
Num banco de dados distribuídos os arquivos podem estar replicados ou fragmentados, esses dois tipos podem ser encontrados aos longos dos nós do sistema de BDD's. Quando os dados se encontram replicados, existe uma cópia de cada um dos dados em cada nó, tornando as bases iguais (ex: tabela de produtos de uma grande loja). Já na fragmentação, os dados se encontram divididos ao longo do sistema, ou seja, a cada nó existe uma base de dados diferente se olharmos de uma forma local, mas se analisarmos de uma forma global os dados são vistos de uma forma única, pois cada nó possui um catálogo que contém cada informação dos dados dos bancos adjacentes.
A replicação dos dados pode se dar de maneira síncrona ou assíncrona. No caso de replicação síncrona, cada transação é dada como concluída quando todos os nós confirmam que a transação local foi bem-sucedida. Na replicação assíncrona, o nó principal executa a transação enviando confirmação ao solicitante e então encaminha a transação aos demais nós.
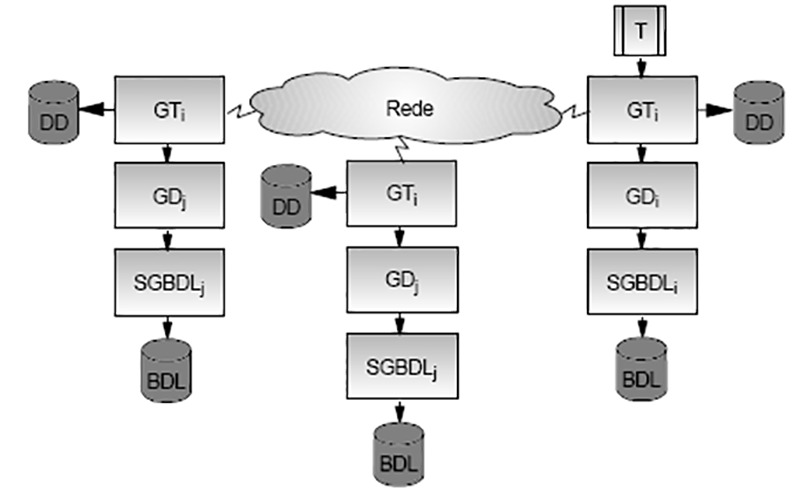
Arquitetura Básica
-
Usuários acessam banco de dados distribuídos através:
Aplicações Locais
Aplicações que não requerem dados de outros lugares.
Aplicações Globais
Aplicações que requerem dados de outros lugares.
Importantes considerações
- A distribuição é transparente — usuários devem poder interagir com o sistema como se ele fosse um único sistema lógico. Isso se aplica ao desempenho do sistema, métodos de acesso, entre outras coisas.Transações são transparentes — cada transação deve manter a integridade do banco de dados dentre os múltiplos bancos de dados. Transações devem também ser divididas em subtransações, cada subtransação afetando um sistema de banco de dados...
Cuidado com banco de dados distribuídos devem ser tomados para assegurar o seguinte:
Vantagens de bancos de dados distribuídos
Disponibilidade
- – ao contrário da arquitetura centralizada, na arquitetura distribuída a ocorrência de uma falha em um dos sítios não deixa inoperável todo o BD. Alguns dados tornam-se inatingíveis, mas outras partes do BD podem ser acessadas.
Autonomia Local
- — um departamento pode controlar seus dados (já que é o mais familiarizado com estes).
Maior disponibilidade
- — uma falha em um banco de dados afetará somente um fragmento, ao invés do banco de dados inteiro.
Melhor performance
- — os dados estão localizados próximo do local de maior demanda e os sistemas de banco de dados por si só são paralelizáveis, permitindo carregar no banco de dados para o balanceamento entre servidores (a elevada carga em um módulo do banco de dados não irá afetar os outros módulos de banco de dados em um banco de dados distribuído).
Melhor Desempenho
- – quando um grande BD é distribuído em vários sítios, existem BD menores em cada sítio. Por este motivo, consultas e transações que acessam os dados em um único sítio têm melhor desempenho. Além disso, cada sítio tem um número menor de transações em execução do que no caso de todas as transações serem submetidas a um único BD centralizado.
Econômico
- — custa menos criar uma rede de pequenos computadores com o mesmo poder que um único computador maior.
Modularidade
- — sistemas podem ser modificados, adicionados ou removidos do banco de dados distribuído sem afetar os outros módulos (sistemas).
Desvantagens de banco de dados distribuídos
- Autonomia Local — um departamento pode controlar seus dados (já que é o mais familiarizado com estes).Maior disponibilidade — uma falha em um banco de dados afetará somente um fragmento, ao invés do banco de dados inteiro.
Complexidade — trabalho extra deve ser feito pelos DBAs para garantir que a natureza da distribuição do sistema é transparente. Trabalho extra deve ser feito para manter sistemas múltiplos diferentes, ao invés de um único grande. Design de banco de dados extra deve também ser feito para levar em conta a natureza desconectada do banco de dados - por exemplo, joins tornam-se proibitivamente caros quando são rodados entre múltiplas plataformas.
Implantação mais cara — o aumento da complexidade e uma infra-estrutura mais extensa significa custo extra de trabalho
Segurança — fragmentos de banco de dados remotos devem ser seguros e, como eles não são centralizados então os lugares remotos também devem ser seguros. A infra-estrutura também deve ser segura (por exemplo, pela encriptação dos links de rede entre os lugares remotos).
Difícil de manter a integridade — em sistemas distribuídos, reforçar a integridade ao longo de uma rede pode exigir demais dos recursos da rede para ser viável.
Inexperiência — pode ser difícil trabalhar com banco de dados distribuídos e como é uma área relativamente nova ainda não há tantos casos (ou experiências) práticos de seu uso disponíveis como exemplo.
Falta de padrões – ainda não há metodologias e ferramentas para ajudar usuários a converter um SGBD centralizado para um SGBD distribuído.
Design do banco de dados mais complexa – além das dificuldades normais, o design de um banco de dados distribuídos tem que considerar a fragmentação dos dados, alocação dos fragmentos em lugares específicos e a replicação de dados.
SGBDs para Estações Móveis
-
Características:
topologia:
um backbone fixo com estações de controle também fixas conjunto de células nas quais transitam as estações móveis.
localização dos dados:
dados residem tanto nas estações fixas quanto nas móveis ("walkstations")

Manutenção do Diretório:
-
Problema:
Como localizar as estações móveis que contêm os dados desejados Alternativas:
Armazenar a localização da estação móvel apenas na sua estação de base distribuir a informação sobre a localização das estações móveis pre-anunciar o roteiro de cada estação móvel
Caching:
Problema:
Limite da bateria da estação móvel impõe restrições sobre o grau de caching
Alternativas:
Mover consultas para estações fixas, transferindo apenas resultados adotar filtros semânticos mais sofisticados para reduzir o tamanho do cachê.
Publicado em
Banco de Dados
Quinta, 08 Setembro 2016 18:45
MySQL

O MySQL é um sistema de gerenciamento de banco de dados (SGBD), que utiliza a linguagem SQL (Linguagem de Consulta Estruturada, do inglês Structured Query Language) como interface. É atualmente um dos bancos de dados mais populares, com mais de 10 milhões de instalações pelo mundo.
Entre os usuários do banco de dados MySQL estão: NASA, Friendster, Banco Bradesco, Dataprev, HP, Nokia, Sony, Lufthansa, U.S. Army, U.S. Federal Reserve Bank, Associated Press, Alcatel, Slashdot, Cisco Systems, Google e outros.
História
O MySQL foi criado na Suécia por dois suecos e um finlandês: David Axmark, Allan Larsson e Michael "Monty" Widenius, que têm trabalhado juntos desde a década de 1980. Hoje seu desenvolvimento e manutenção empregam aproximadamente 400 profissionais no mundo inteiro, e mais de mil contribuem testando o software, integrando-o a outros produtos, e escrevendo a respeito dele.
No dia 16 de Janeiro de 2008, a MySQL AB, desenvolvedora do MySQL foi adquirida pela Sun Microsystems, por US$ 1 bilhão, um preço jamais visto no setor de licenças livres. No dia 20 de Abril de 2009, foi anunciado que a Oracle compraria a Sun Microsystems e todos o seus produtos, incluindo o MySQL. Após investigações da Comissão Europeia sobre a aquisição para evitar formação de monopólios no mercado a compra foi autorizada e hoje a Sun faz parte da Oracle.
O sucesso do MySQL deve-se em grande medida à fácil integração com o PHP incluído, quase que obrigatoriamente, nos pacotes de hospedagem de sites da Internet oferecidos atualmente. Empresas como Yahoo! Finance, MP3.com, Motorola, NASA, Silicon Graphics e Texas Instruments usam o MySQL em aplicações de missão crítica. A Wikipédia é um exemplo de utilização do MySQL em sites de grande audiência.
O MySQL hoje suporta Unicode, Full Text Indexes, replicação, Hot Backup, GIS, OLAP e muitos outros recursos de banco de dados.
Características
- Portabilidade (suporta praticamente qualquer plataforma atual);
- Compatibilidade (existem drivers ODBC, JDBC e .NET e módulos de interface para diversas linguagens de programação, como Delphi, Java, C/C++, C#, Visual Basic, Python, Perl, PHP, ASP e Ruby)
- Excelente desempenho e estabilidade;
- Pouco exigente quanto a recursos de hardware;
- Facilidade de uso;
- É um Software Livre com base na GPL (entretanto, se o programa que acessar o Mysql não for GPL, uma licença comercial deverá ser adquirida);
- Contempla a utilização de vários Storage Engines como MyISAM, InnoDB, Falcon, BDB, Archive, Federated, CSV, Solid…
- Suporta controle transacional;
- Suporta Triggers;
- Suporta Cursors (Non-Scrollable e Non-Updatable);
- Suporta Stored Procedures e Functions;
- Replicação facilmente configurável;
- Interfaces gráficas (MySQL Toolkit) de fácil utilização cedidos pela MySQL Inc.
MySQL
DesenvolvedorOracle Corporation
Sistema OperacionalMultiplataforma
Gênero(s)SGBD
LicençaGPL e Licença comercial
Página oficial www.mysql.com
Download
http://dev.mysql.com/downloads/mysql/
Fonte: Wikipedia
Publicado em
Banco de Dados
Quinta, 08 Setembro 2016 18:27
Banco de Dados

Bancos de dados, ou bases de dados, são coleções de dados que se relacionam de forma que crie um sentido. São de vital importância para empresas, e há duas décadas se tornaram a principal peça dos sistemas de informação. Normalmente existem por vários anos sem alterações em sua estrutura.
São operados pelos Sistemas Gerenciadores de Bancos de Dados (SGBD), que surgiram na década de 70.Antes destes, as aplicações usavam sistemas de arquivos do sistema operacional para armazenar suas informações.Na década de 80 a tecnologia de SGBD relacional passou a dominar o mercado, e atualmente utiliza-se praticamente apenas ele.Outro tipo notável é o SGBD Orientado a Objetos, para quando sua estrutura ou as aplicações que o utilizam mudam constantemente.
A principal aplicação de Banco de Dados é controle de operações empresariais.Outra aplicação também importante é gerenciamento de informações de estudos, como fazem os Bancos de Dados Geográficos, que unem informações convencionais com espaciais.
Modelos de base de dados
O modelo plano (ou tabular) consiste de matrizes simples, bidimensionais, compostas por elementos de dados: inteiros, números reais, etc. Este modelo plano é a base das planilhas eletrônicas.
O modelo em rede permite que várias tabelas sejam usadas simultaneamente através do uso de apontadores (ou referências). Algumas colunas contêm apontadores para outras tabelas ao invés de dados. Assim, as tabelas são ligadas por referências, o que pode ser visto como uma rede. Uma variação particular deste modelo em rede, o modelo hierárquico, limita as relações a uma estrutura semelhante a uma árvore (hierarquia - tronco, galhos), ao invés do modelo mais geral direcionado por grafos.
Bases de dados relacionais consistem, principalmente de três componentes: uma coleção de estruturas de dados, nomeadamente relações, ou informalmente tabelas; uma coleção dos operadores, a álgebra e o cálculo relacionais; e uma coleção de restrições da integridade, definindo o conjunto consistente de estados de base de dados e de alterações de estados. As restrições de integridade podem ser de quatro tipos: domínio (também conhecidas como type), atributo, relvar (variável relacional) e restrições de base de dados.
Diferentemente dos modelos hierárquico e de rede, não existem quaisquer apontadores, de acordo com o Princípio de Informação: toda informação tem de ser representada como dados; qualquer tipo de atributo representa relações entre conjuntos de dados. As bases de dados relacionais permitem aos utilizadores (incluindo programadores) escreverem consultas (queries) que não foram antecipadas por quem projetou a base de dados. Como resultado, bases de dados relacionais podem ser utilizadas por várias aplicações em formas que os projetistas originais não previram, o que é especialmente importante em bases de dados que podem ser utilizadas durante décadas. Isto tem tornado as bases de dados relacionais muito populares no meio empresarial.
O modelo relacional é uma teoria matemática desenvolvida por Edgard Frank Codd, matemático e pesquisador da IBM, para descrever como as bases de dados devem funcionar. Embora esta teoria seja a base para o software de bases de dados relacionais, muito poucos sistemas de gestão de bases de dados seguem o modelo de forma restrita ou a pé da letra - lembre-se das 12 leis do modelo relacional - e todos têm funcionalidades que violam a teoria, desta forma variando a complexidade e o poder. A discussão se esses bancos de dados merecem ser chamados de relacional ficou esgotada com o tempo, com a evolução dos bancos existentes. Os bancos de dados hoje implementam o modelo definido como objeto-relacional.
Aplicações de bancos de dados
Sistemas Gerenciadores de Bancos de dados são usados em muitas aplicações, enquanto atravessando virtualmente a gama inteira de software de computador. Os Sistemas Gerenciadores de Bancos de dados são o método preferido de armazenamento/recuperação de dados/informações para aplicações multi-usuárias grandes onde a coordenação entre muitos usuários é necessária. Até mesmo usuários individuais os acham conveniente, entretanto, muitos programas de correio eletrônico e organizadores pessoais estão baseados em tecnologia de banco de dados standard.
Transação
É um conjunto de procedimentos que é executado num banco de dados, que para o usuário é visto como uma única ação. A integridade de uma transação depende de 4 propriedades, conhecidas como ACID.
- Atomicidade: Todas as ações que compõem a unidade de trabalho da transação devem ser concluídas com sucesso, para que seja efetivada. Se durante a transação qualquer ação que constitui unidade de trabalho falhar, a transação inteira deve ser desfeita (rollback). Quando todas as ações são efetuadas com sucesso, a transação pode ser efetivada e persistida em banco (commit).
- Consistência: Todas as regras e restrições definidas no banco de dados devem ser obedecidas. Relacionamentos por chaves estrangeiras, checagem de valores para campos restritos ou únicos devem ser obedecidos para que uma transação possa ser completada com sucesso.
- Isolamento: Cada transação funciona completamente à parte de outras estações. Todas as operações são parte de uma transação única. O principio é que nenhuma outra transação, operando no mesmo sistema, possa interferir no funcionamento da transação corrente(é um mecanismo de controle). Outras transações não podem visualizar os resultados parciais das operações de uma transação em andamento (ainda em respeito à propriedade da atomicidade).
- Durabilidade: Significa que os resultados de uma transação são permanentes e podem ser desfeitos somente por uma transação subseqüente.Por exemplo: todos os dados e status relativos a uma transação devem ser armazenados num repositório permanente, não sendo passíveis de falha por uma falha de hardware.
Na prática, alguns SGBDs relaxam na implementação destas propriedades buscando desempenho.
Controle de concorrência é um método usado para garantir que as transações sejam executadas de uma forma segura e sigam as regras ACID. Os SGBD devem ser capazes de assegurar que nenhuma ação de transações completadas com sucesso (committed transactions) seja perdida ao desfazer transações abortadas (rollback).
Uma transação é uma unidade que preserva consistência. Requeremos, portanto, que qualquer escalonamento produzido ao se processar um conjunto de transações concorrentemente seja computacionalmente equivalente a um escalonamento produzindo executando essas transações serialmente em alguma ordem. Diz-se que um sistema que garante esta propriedade assegura a seriabilidade.
Segurança em banco de dados
Os bancos de dados são utilizados para armazenar diversos tipos de informações, desde dados sobre uma conta de e-mail até dados importantes da Receita Federal. A segurança do banco de dados herda as mesmas dificuldades que a segurança da informação enfrenta, que é garantir a integridade, a disponibilidade e a confidencialidade. Um Sistema gerenciador de banco de dados deve fornecer mecanismos que auxiliem nesta tarefa.
Uma forma comum de ataque à segurança do banco de dados, é a injeção de SQL, em bancos de dados que façam uso desta linguagem, mas bancos de dados NoSQL também podem ser vítimas. Para evitar estes ataques, o desenvolvedor de aplicações deve garantir que nenhuma entrada possa alterar a estrutura da consulta enviada ao sistema.
Os bancos de dados SQL implementam mecanismos que restringem ou permitem acessos aos dados de acordo com papeis ou roles fornecidos pelo administrador. O comando GRANT concede privilégios específicos para um objeto (tabela, visão, seqüência, banco de dados, função, linguagem procedural, esquema ou espaço de tabelas) para um ou mais usuários ou grupos de usuários.
Fonte: Wikipedia
Publicado em
Banco de Dados